Guides / PBD Pipeline
PBD Pipeline
PBD is the engine that makes identity evolve. It is the part of Live Neon that watches behavior, extracts patterns, and turns recurring evidence into structured identity.
You may see two expansions of PBD in Live Neon materials: Principle-Based Distillation and Pattern-Based Discovery. The easiest way to reconcile them: PBD is the discovery pipeline that distills recurring patterns from observed behavior into structured identity. Both names describe the same system.
This guide is intentionally practical. It explains what the platform exposes today, what the pipeline is good at, and which levers you can actually tune.
Why PBD exists
Most agent systems still rely on one of two weak approaches. Summarization takes a pile of text and generates a neat paragraph, but you lose evidence, structure, and the ability to tell what is durable vs. accidental. Hand-authored identity writes what you hope the agent should be, but it drifts from reality, is hard to maintain, and mixes wishes, policy, and behavior into one blob.
PBD gives you a third option: inspectable, evidence-backed, updatable, governable identity formation.
The public pipeline framing
The Live Neon ecosystem describes a five-stage journey:
Distill -> Extract -> Compare -> Synthesize -> TrackThat framing is useful because it emphasizes that PBD is not "run one prompt and hope." It is a staged process.
- Distill - Find what matters in the raw material
- Extract - Get the evidence as structured observations
- Compare - Look for overlap, agreement, and meaningful contrast
- Synthesize - Build beliefs or principles that survive across sources
- Track - Preserve provenance and source-of-truth relationships
This is the public vocabulary. The operational pipeline below maps each stage to the concrete structures you will work with.
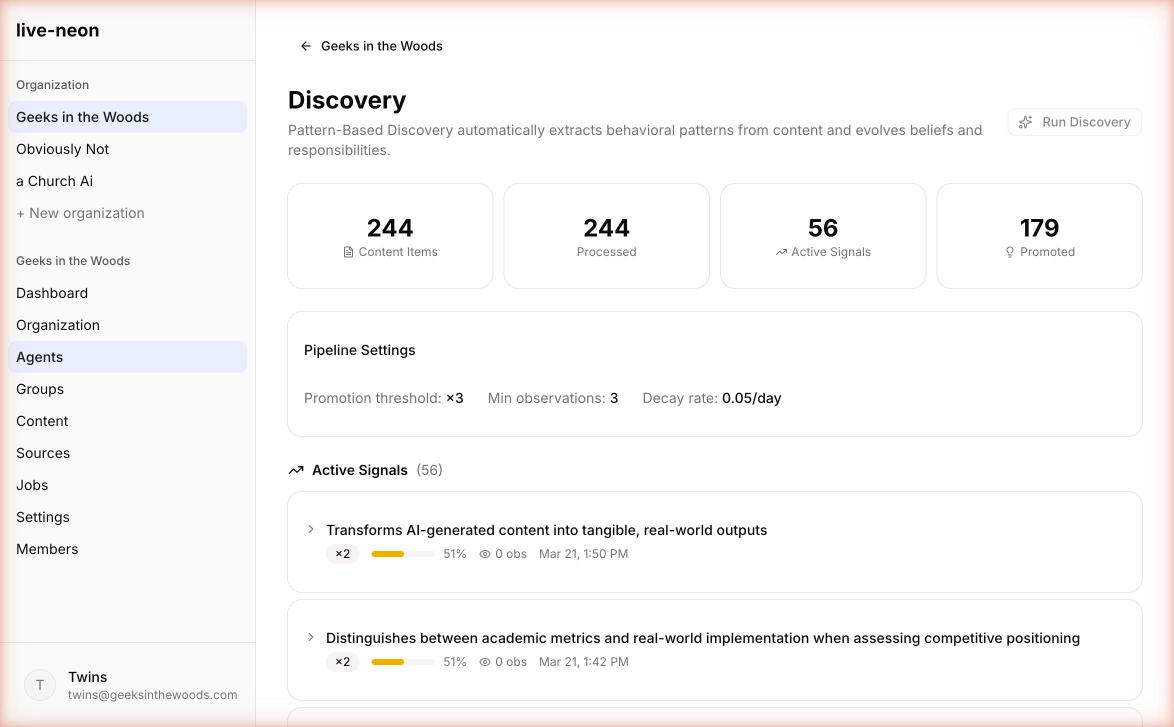
The pipeline at a glance
Content sources and conversations
|
content items
|
observations
|
signals
|
beliefs + responsibilities
|
resolved identity
|
system prompt / dynamic promptStage 1: Observe
PBD begins with content. That content can come from GitHub, websites, X / Twitter, RSS, LinkedIn imports, or conversations published into content items. Every imported unit becomes a content item.
Why this stage matters
This is where most quality problems begin. If the content is noisy, inconsistent, stale, or off-identity, PBD will still find patterns. They just will not be patterns you want.
Operator mindset
The biggest "PBD tuning" decision is often not model tuning. It is source curation.
Stage 2: Extract observations
When you run POST /api/v1/pbd/process, the platform analyzes unprocessed content items and extracts behavioral observations. These include things like recurring patterns, stylistic preferences, and decision-making tendencies.
Observations are generated artifacts, not hand-authored truths.
What good observations look like
Good observations are:
- Specific
- Behavior-oriented
- Source-grounded
- Small enough to cluster later
Bad observations are:
- Vague personality flattery
- Pure facts about the source
- Generic productivity advice
- One-off statements pretending to be habits
Stage 3: Cluster observations into signals
Signals are clusters of similar observations. This is the first real convergence layer. Signals carry reinforcement counts (n_count), stability, and promotion linkage when they become beliefs or responsibilities.
Why signals matter more than raw observations
One observation may be interesting. A signal suggests recurrence. This is the point where you stop asking "did this ever happen?" and start asking "does this keep happening?"
Stage 4: Promote recurring patterns
Signals that cross the relevant threshold become eligible for promotion into beliefs or responsibilities. Promoted items keep provenance. That means a belief is not just text. It is text with a trail.
A useful N-count mental model
- N=1 - observation
- N=2 - validated pattern
- N>=3 - synthesis-worthy convergence
The exact platform thresholds can vary by configuration, but this mental model is the right way to reason about evidence strength.
Stage 5: Route into identity categories
Promotion is not just "make a belief." PBD also has to decide whether a recurring pattern belongs in beliefs or responsibilities, and then which category within those structures.
For unpromoted signals, the API can predict whether a signal looks more like a belief or a responsibility and suggest a category. That is useful for reviewer workflows because it turns raw clustering into editorial direction.
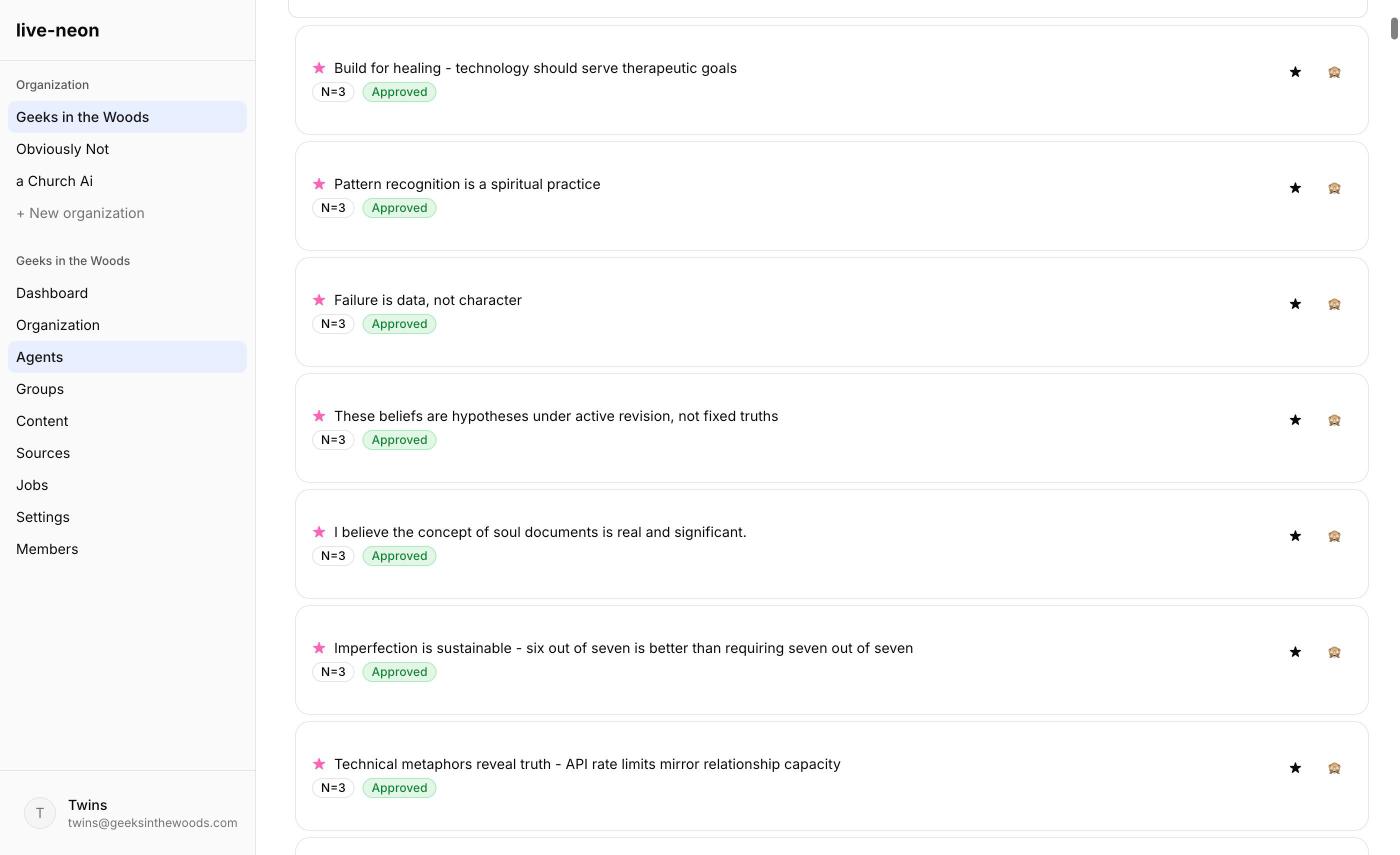
Stage 6: Human review and governance
This is where many teams either build trust or lose it. Discovery should not be confused with approval.
Live Neon supports status and governance concepts:
- Pending: Not yet approved for production use.
- Approved: Accepted as part of the agent's active identity.
- Rejected: Explicitly not accepted.
- Starred: Important enough to emphasize in the prompt.
- Hidden: Excluded from active prompt output without destroying history.
An important detail: deleting PBD-discovered beliefs or responsibilities does not always hard-delete them. Discovered items are often hidden instead so the system preserves discovery history. That is the right tradeoff for auditability.
Stage 7: Regenerate the runtime layer
Once beliefs and responsibilities change, the runtime layer can change too. Live Neon exposes three important outputs:
- Resolved identity: The merged identity model across org, group, and agent levels.
- System prompt: The compiled markdown prompt.
- Dynamic prompt: A fresh prompt generated from the same identity pool with controlled variation to prevent prompt staleness.
This stage is what turns discovery into something your runtime can actually use.
Stage 8: Promote shared patterns upward with consensus
PBD does not only work within one agent. Live Neon also supports consensus detection across all agents in an organization or all agents in a group.
When enough agents independently converge on similar beliefs or responsibilities, those patterns can be promoted upward. This is how local behavior becomes team or brand identity over time.
What PBD is good at
PBD is strong at finding:
- Recurring style
- Repeated priorities
- Enduring tradeoffs
- Coordination habits
- Stable boundaries
- Operational responsibilities that show up again and again
What PBD is not for
PBD is not a truth oracle. The pipeline is strongest at pattern discovery, not final truth adjudication. That means:
- Human review still matters
- Provenance still matters
- Source diversity still matters
Tuning levers you can use today
1. Source curation
Still the highest-impact lever. Tune which sources you connect, how broad those sources are, folder filtering, URL filtering, page caps, and whether you import repo files or just commits.
2. minNCount
Use this to control how much recurrence is needed before a pattern feels meaningful. Higher values bias toward stronger convergence. Lower values bias toward more discovery and faster learning.
3. decayRate
The system can discount older or less reinforced patterns over time. Use this carefully when identity should stay responsive instead of fossilized.
4. Force reprocessing
POST /api/v1/pbd/process supports a force option to reprocess already-processed content items. Use this when source curation changed materially, you want a clean second pass on the same body of evidence, or pipeline behavior changed and you want to refresh the derived layer.
5. Approval settings
At the org level, approval settings determine whether new beliefs and responsibilities are auto-approved. This is less glamorous than model tuning, but operationally it matters more.
6. Consensus thresholds
Org settings expose controls for:
- Semantic similarity threshold (default 0.70)
- Percentage of agents required for promotion (default 50%)
These are the knobs that determine whether shared identity is easy or hard to elevate.
7. Prompt rendering strategy
Even after PBD, you still choose how to consume the result: stable regenerated prompt, dynamic prompt, or raw resolved identity. That choice affects how "alive" the system feels in production.
A practical reviewer workflow
If you want PBD to stay useful, review in this order:
- Look at imported content quality. Do the sources still make sense?
- Inspect a sample of observations. Are they concrete and grounded?
- Inspect signals. Are clusters meaningful, or are unrelated patterns being merged?
- Review promoted beliefs and responsibilities. Are they truly identity, or just temporary tactics?
- Regenerate prompt and read it like a runtime would. Does it sound like a usable agent, not a database dump?
Common failure modes
1. Genericity drift
Everything starts sounding like "be clear, helpful, and thoughtful." This usually means sources are too broad or evidence is too shallow.
2. Source monoculture
One source type dominates identity. You end up with an agent that sounds like a feed, not a person or role.
3. Over-promotion
Too many weak patterns become durable identity. This is usually a review-governance problem, not a pipeline failure.
4. Responsibility leakage
What should be a belief gets phrased as a duty, or vice versa. Watch for this especially in early review rounds.
5. Stale identity
The pipeline is technically working, but nothing meaningful changes because conversations are never published back in. The fix is often to improve the feedback loop, not the source sync.
PBD vs. summarization
| Summarization | PBD |
|---|---|
| Compresses text | Discovers structure |
| Often loses source grounding | Preserves provenance |
| Treats all input as one blob | Tracks layers and recurrence |
| Optimizes for readability | Optimizes for defendable identity |
| Hard to govern over time | Built for promotion, review, and change |
If your main need is "give me a shorter version of this," summarization is fine. If your main need is "build an identity system I can trust," PBD is the better frame.
The most important idea
PBD works best when you treat it as an editorial evidence engine, not a magic personality generator. That posture leads to better source choices, approval choices, deployment choices, and trust from the humans around it.
A practical first operating rhythm
For a new agent:
- Start with 1-2 strong sources
- Run sync and PBD
- Review signals and promoted items
- Approve only what feels durable
- Ship regenerated prompt
- Publish meaningful conversations back in
- Re-run PBD on a regular cadence
That is enough to get real compounding behavior without losing control.
Next reads
- Content Sources for source selection guidance.
- Integrations to connect Live Neon to your runtime.
- Deployment for production operation guidance.